МОДЕЛЬ СИСТЕМЫ СИНТЕЗА ПАРАМЕТРОВ РЕЧИ
ПО ПЕЧАТНОМУ ТЕКСТУ С ИСПОЛЬЗОВАНИЕМ
ИНФОРМАЦИОННЫХ ПРЕДСТАВЛЕНИЙ
Р.В. Мещеряков
1. ВВЕДЕНИЕ
В настоящее время задача синтеза речи по печатному тексту полностью не решена и имеет ряд сложностей, которые заслуживают детального рассмотрения. Некоторым из них посвящена данная работа.
При создании систем синтеза речи возникают вопросы разработки как устройств, воспроизводящих речь, так и математического аппарата, описывающего поведение системы генерации речевого сигнала. В качестве исходной модели выбран синтез речи по правилам. Исходными параметрами для системы синтеза речи являются: орфографически правильный печатный текст; характеристики речеобразующего тракта человека. На выходе системы синтеза речи должен быть получен речевой сигнал.
В частности, наибольшую сложность представляет собой генерация просодических параметров речи и являются необходимыми для создания качественного естественного речевого сигнала. Они включают в себя длительности звуков, изменение частоты основного тона и др.
Синтез речи является сложной задачей, использующей различного рода информацию. Рассмотрим модель представления речи.
2. ИЕРАРХИЧЕСКОЕ ПРЕДСТАВЛЕНИЕ
Печатный текст и речевой сигнал имеют ярко выраженную иерархическую природу [1-5]. Данное свойство позволяет использовать особенности, присущие этому классу систем
[6]. Для достижения наибольшей эффективности система должна использовать отмеченное свойство. Один из общих вариантов схемы преобразований приведен на рис.1.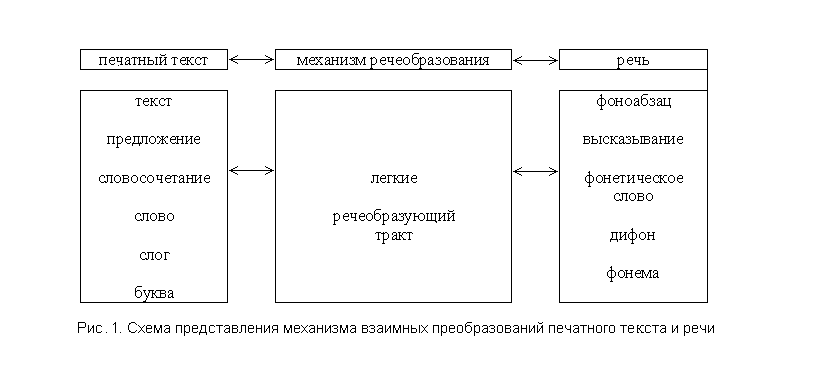
Рассмотрим чтение текста человеком. Человек генерирует по тексту параметры, необходимые для настройки речеобразующего тракта и легких. При произнесении человеком печатного текста происходит разложение текста на его исходные составляющие, которые могут быть представлены в иерархическом виде (см. схема на рис.1 под блоком “печатный текст”), в свою очередь, произносимая речь также имеет ярко выраженную иерархическую структуру, (см. схема на рис. 1 под блоком “речь”). Весь процесс преобразования человеком происходит на основе механизма речеобразования путем изменения параметров речеобразующего тракта и легких.
Человек произносит звуки и слова не задумываясь над тем, как расположить органы речеобразования. Настройку системы речеобразования можно наблюдать у детей, которые учатся говорить.
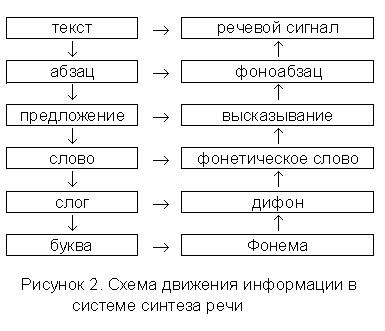
Используя иерархическое представление можно сказать, что для качественного построения систем синтеза речи необходимо создать модель механизма речеобразования. Первоначально определим в системе движение информации, которое должно происходить по схеме, представленной на рис. 2.
При использовании приведенной выше модели движения информации в системе необходимо корректно устанавливать соответствие между уровнями орфографического текста и речи. Это позволяет перейти от символьной информации, заложенной в тексте, к параметрам речеобразующего тракта и, собственно, к численным значениям речевого сигнала, имеющим конкретные значения изменения частоты основного тона, ритмики (времени произнесения звуков и продолжительность пауз) и энергии. Рассмотрим последовательность преобразований, которая использовала бы данное представление речи.
3. ПОСЛЕДОВАТЕЛЬНОСТЬ ПРЕОБРАЗОВАНИЯ ТЕКСТА В РЕЧЬ
В системах синтеза речи происходит преобразование исходного печатного текста в последовательность управляющих кодов для устройства, генерирующего речевой сигнал. С целью создания такого рода устройств нужно определить необходимое и достаточное количество параметров, позволяющих создавать человекоподобную речь.
При произнесении речи изменяется во времени амплитудно-частотная и фазо-частотная характеристики речевого сигнала. Особо необходимо выделить такие характеристики, как: частота основного тона, представляющая собой самую низкую частоту, присутствующую в речевом сигнале и форманты. Данные параметры являются результатом прохождения воздуха под давлением, возникающим в легких по речеобразующему тракту человека. Наиболее полная модель, в которую можно внести влияние большинства характеристик речеобразующего тракта, - синтез речи по правилам. В данной модели могут быть заданы неизменяемые характеристики, такие как объем легких, средняя длина тракта и другие (см. рис.1 под блоком “механизм речеобразования”). Практически получается система, имеющая правила преобразований типа (см. рис. 1, верхний уровень).
Рассмотрим механизм речеобразования на уровне возникновения управляющих воздействий. До произнесения высказывания у человека формируется общая образная картина высказывания, ее коммуникативная необходимость. В соответствии с этими и другими параметрами (например, эмоции, соответствующие высказыванию) создается интонационное оформление. Далее человек начинает произносить слова, управляя давлением воздуха в легких и параметрами речеобразующего тракта (длина гортани, положение языка, губ и др.). Управление подбирается таким образом, чтобы наиболее информативные участки высказывания были выделены. Наиболее часто это выделение носит характер повышения частоты основного тона и повышенной четкости произнесения этих участков. В результате получается, что важные участки выделены, а все переходы между звуками сглажены, и общая картина высказывания может быть воспринята слушающим.
При использовании данного подхода в системах синтеза речи при преобразовании печатного текста в речевой сигнал должны последовательно выполняться следующие этапы в приведенной ниже последовательности
[3]:При выполнении всех этапов должны быть заданы характеристики, необходимые для его реализации, например, для расчета частоты основного тона, желательно иметь информацию по границам частотного диапазона, пол человека, объем и время реакции легких и другие. Таким образом, при полном и правильном выполнении всех этапов будут созданы все параметры, зависящие от конкретного высказывания для устройства, генерирующего речевой сигнал.
4. МАТЕМАТИЧЕСКОЕ ОПИСАНИЕ
Как отмечалось выше, задача преобразования печатного текста в речевой сигнал сводится к задаче нахождения отображения упорядоченной последовательности символов из алфавита языка и служебных знаков в последовательность воздействий на устройство воспроизведения речи, т.е.
![]() , (1)
, (1)
где T - исходный печатный текст, каждый элемент которого t входит в алфавит языка S, либо в множество служебных знаков; R - последовательность воздействий на устройство воспроизведения, каждый элемент которого представляет собой вектор параметров, необходимых для управления устройством воспроизведения речевого сигнала. По [7] установим, что элементы, составляющие непересекающиеся множества S, Z и L, - образующие, а множества - классы образующих.
У каждого класса образующей имеются свои признаки, определяющие ее свойства и свойства объекта, состоящего из образующих класса. Внутри объекта “текст” буквы имеют такой основной признак, как наименование. Для класса “речь” выделим признак уровня сигнала во времени. Переход от шкал, выраженных в наименованиях, к численным шкалам должен проводиться в соответствии со связями, устанавливаемыми между образующими входных и выходных классов по (2).
![]() , (2)
, (2)
где p() - признаки.
При построении связей внутри исходного объекта текста возникают сложности, связанные с учетом влияния различных видов информационной структуры текста. Существующие связи внутри текста накладывают ограничения на использование преобразований образующих различных классов. Особую сложность при рассмотрении представляют собой связи, имеющие по [1,2] свойства внутри текста, зависящие от субъекта их интерпретации. Человек, используя различные виды информации (семантическую, прагматическую и др.), легко преобразует текст в зависимости от контекста в речевой сигнал. При недостатке информации (например, при встрече незнакомых слов) человек произносит максимально нейтрально, т.е. практически устанавливается непосредственная связь между образующими класса текста и речевого сигнала.
Наиболее целесообразным представляется вариант создания образующих классов, отличных от входного и выходного со свойствами, отграничивающими использование различных видов информации при построении связей по (3).
![]() , (3)
, (3)
Необходимо отметить, что часть свойств исходного множества не оказывает влияния на промежуточные преобразования и остается без изменения.
Исследования показали, что в качестве образующих должны рассматриваться элементы различных уровней понимания текста и речи. Для разбиения связного множества T (исходного печатного текста) выделяется ряд символов, имеющих общие связи при различны уровнях понимания текста, например, на синтаксическом уровне выделяем образующие s из множества словоформ S. Иерархическое представление информации позволяет выделять для образующих данного уровня необходимое и достаточное количество свойств, обеспечивающее полное преобразование информации по всем уровням понимания текста и речи.
При синтезе sÎ S из tÎ T по [3] признаки полученных образующих можно представить в виде (4).
![]() , (4)
, (4)
Функция F() выбирается в зависимости от уровня понимания и степени связности исходных образующих
[8].Критериями правильности построения связей как внутри объекта образующих исходного класса, так и между объектами различных классов может служить целевая функция (5).
![]() , (5)
, (5)
где i - номер этапа промежуточных преобразований, n - количество этапов, K
i - коэффициент, зависящий от влияния i-го этапа на результат.Таким образом, по заданной модели, представленной на рис. 1, и заданной последовательности преобразований созданное математическое описание может быть реализовано.
5. РЕАЛИЗАЦИЯ
В качестве основного подхода было выбрано структурное программирование, выполняющее часть этапов преобразования печатного текста в речевой сигнал. Они были выполнены как независящие друг от друга модули, что позволяет после работы каждого модуля анализировать результаты, полученные при работе, и корректировать внутренние алгоритмы, не изменяя остальные модули.
При решении первого этапа было найдено, что в русском языке ударным может быть любой слог слова. Имеются обширные сведения о местоположении ударения в различных частях речи и при их изменении. Была проведена попытка использования распознающих контекстно-свободных грамматик, но она закончилась неудачно, т.к. исходя из изложенных выше сведений, можно сказать, что нельзя использовать механизмы, предоставляемыми контекстно-свободными грамматиками для распознавания местоположения ударного слога, т.к. правила вывода не могут быть полностью формализованы. Не представляется возможным использовать словарь исключений из правил, которые выводили бы результат местоположения ударного слога только из части речи, его свойств и местоположения в предложении, а также просто расстановка по наиболее вероятному местоположению ударного слога в слове. Ввиду большого количества слов русского языка было решено использовать словарь для наиболее часто встречающихся слов.
Расстановка ударений осуществляется в три этапа. На первом расставляются ударения для слов из словаря. На следующем этапе в случае малого количества (менее 50%) расставленных ударений в словах используется расстановка в местах наиболее часто встречаемых ударений в словах (используя ритмические структуры). На последнем этапе расставляются ударения по ритмике, т.е. чтобы ударения в произносимой фразе были, по возможности, равномерные. Примером может служить белый стих, который не имеет рифмы, но имеет ритмическую структуру, т.е. ударения или выделенные гласные идут приблизительно через равные промежутки времени. Данное правило использует свойство ритмичности человеческой речи. Этим правилом в системе достигается плавность и ритмичность произносимой фразы.
Для решения задачи транскрибирования текста требуется орфографически правильно составленный текст и последовательность ударных слогов. В основе алгоритмов фонетической транскрипции лежит общая идеология, хотя второстепенные вопросы решаются индивидуально. Большинство из имеющихся способов транскрибирования описаны вербально для человека. Были разработаны правила транскрибирования, удобные для использования при программировании на процедурных языках. Используется словарь исключений для слов, которые не могут быть правильно транскрибированы обычными правилами. После транскрибирования получаем фонетическую запись текста.
Для решения задачи расчета длительности звуков используется библиотека длительности звуков в зависимостях: для гласных - от ударения, для согласных - от мягкости/твердости. При использовании библиотеки длительностей оказывается возможным учитывать конкретные параметры диктора путем замены библиотеки длительностей на другую. Для развития системы предусмотрено ввести зависимости длительности звуков от коартикуляции и местоположения в синтагме и тексте в целом, а также большую зависимость от параметров голосового тракта диктора: объема легких, длины речеобразующего тракта и др.
При решении задачи расчета частоты основного тона (ЧОТ) выделяются два всплеска на функции изменения ЧОТ: ударные слоги и ударные слова. Величина всплеска на ударном слоге определяется способом постановки ударений: наиболее сильное - по словарю, далее наиболее часто встречающиеся и расставленные - по ритмике.
Были проведены исследования для нахождения правил по выявлению логически ударного слова: этим свойством чаще всего обладают подлежащее и сказуемое. Но широкое использование в русской речи эллиптических конструкций (без подлежащего и/или сказуемого) не позволяют использовать контекстно-свободные грамматики для их определения, а также свойство, что подлежащее и сказуемое могут находиться на различных местах в предложении и на различном расстоянии друг от друга. Поэтому и был использован способ нахождения логически ударного слова по словарю с его априорно известной акцентной значимостью в предложении. Функция изменения получается путем сложения базового значения ЧОТ, всплесков на ударных слогах и логически ударных словах. Базовые значения выбираются в зависимости от знака препинания, которым заканчивается фраза, аппроксимируя функцией Гаусса, и характеристик диктора (средней, максимальной и минимальной значениях ЧОТ). Базовые значения масштабируются в зависимости от длительности высказывания, т.е. при одинаковых типах высказывания, но различных длительностях функция изменения ЧОТ сжималась (для краткого высказывания) или удлинялась (для длительного высказывания).
По разработанным алгоритмам написаны модули в среде программирования
Delphi, что позволяет заменять их другими разработанными модулями и исследовать результаты по каждому модулю и всей системы в целом.6.
ПРИМЕРЫ РЕАЛИЗАЦИИПриведем результаты работы программы по генерации ЧОТ на примере фразы:
“
солнце уже исчезло за горой”.Предварительный расчет длительности высказывания составляет 1894 мс, что не превышает высказывания максимальной длительности, которое может произнести человек, поэтому в разбиении на несколько высказываний нет необходимости.
Результат расстановки ударений приведен в таблице 1.
Таблица 1.
|
Слово |
Номер ударного слога |
Тип ударного слога |
|
солнце |
1 |
1 |
|
уже |
1 |
3 |
|
исчезло |
2 |
2 |
|
за |
1 |
1 |
|
горой |
2 |
2 |
В таблице 1 тип ударного слога определен шагом, на котором находится ударный слог. В словах с типом ударного слога “1” местоположение ударного слога определено по словарю, в словах с типом “2” расстановка проводилась по наиболее вероятным местам, в словах с типом “3” - с использованием ритмических структур.
Следующим этапом является транскрибирование. Результат:
Со
’нцы у’жы ищэ’зла за’ гаро’й
На рисунке 3 приведен результат с расставленными ударениями для повествовательного типа высказывания.
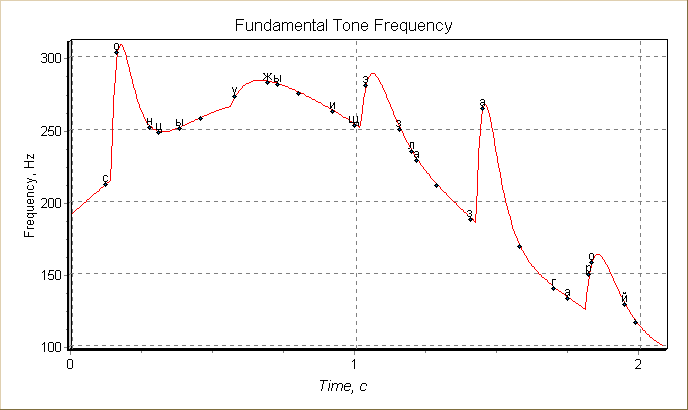
Рис. 3. Повествовательный тип
высказывания, расставленные ударения
Для сравнения высказывания приведем результат для случая с нерасставленными ударениями в словах, результат представлен на рисунке 4.
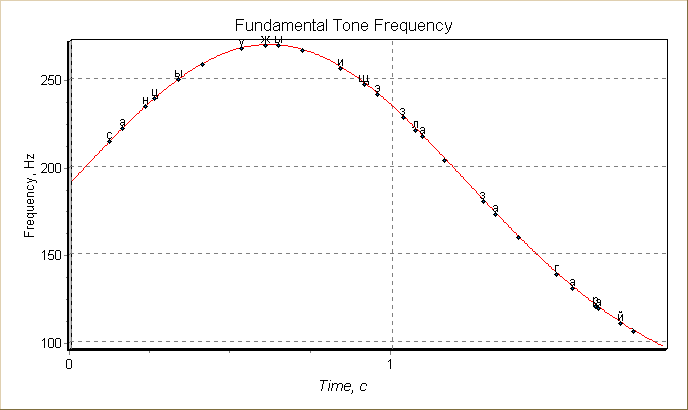
Рис. 4. Повествовательный тип
высказывания, все слова без ударения
На рисунке 5 приведен график для вопросительного типа высказывания.
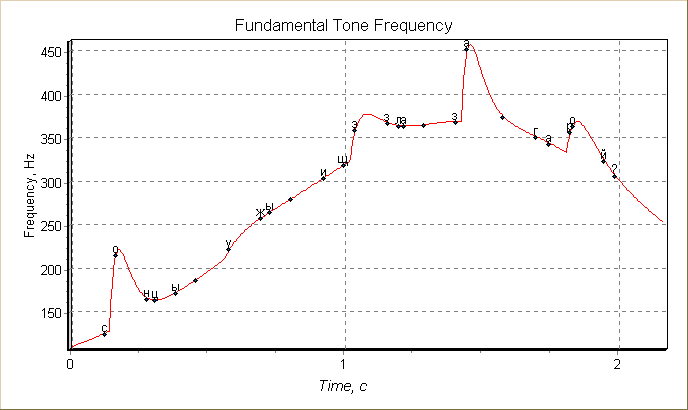
Рис. 5. Вопросительный тип
высказывания, расставленные ударения
Приведенные примеры показывают важность каждого этапа преобразования печатного текста в речевой сигнал.
7. ЗАКЛЮЧЕНИЕ
Проведенные эксперименты позволяют заметить, что не достаточно в общем случае описание отдельных страт. Для каждого конкретного текста и входных параметров формируются структуры на различных стратах. В том случае, когда описание регулярных структур нижних страт перестает удовлетворять условию регулярности, возникает необходимость создания образующих нового, более высокого уровня. В другом случае рассматриваем образующие высокого уровня и, в случае необходимости более детального описания, переходим на описание образующих нижнего уровня.
Информация, необходимая для генерации мелодики основного тона хранится в системе на различных уровнях. В данной реализации информация хранится в соответствующих модулях.
В заключении отметим, что данные принципы используются в системах синтеза и распознания речи. Полученные результаты по их применению показывают целесообразность иерархического подхода к рассмотрению систем подобного типа и построения разбиений на классы.
СПИСОК ЛИТЕРАТУРА
1. Сорокин В.Н. Теория речеобразования. - М.: Радио и связь, 1985. - 312с.
2. Потапова Р.К. Речь: коммуникация, информация, кибернетика: Учеб. пособие для вузов. - М.: Радио и связь. - 1997. - 528с.
3. Мещеряков Р.В., Бондаренко В.П., Заборовский А.Н. Некоторые принципы генерации параметров речевого сигнала в системах синтеза речи// Общие проблемы естественных и точных наук: региональный аспект. Межвузовский сборник научных статей. Бийск: НИЦ БиГПИ, 1998. 106, с 38-42
4. Бондаренко В.П., Коцубинский В.П., Мещеряков Р.В. Синтез речевого сигнала по печатному тексту // Сборник: Автоматическое и автоматизированное управление сложными системами: Сб. статей / Под. ред. В.П. Тарасенко. - Томск: Изд-во Том. ун-та, 1998.-236 с. с.204-217
5. Пиотровский Текст, машина, человек. Л.: Наука, 1975
6. Мессарович М., Мако Д., Такахара И. Теория иерархических многоуровневых систем. /пер. с англ. под ред. И.Ф.Шахнова/ М.: Мир, 1973г
7. Гренандер У. Лекции по теории образов. Кн. 1. Синтез образов, пер. с англ. - М.: Мир, 1979г. - 384с.
8. Дж. Ту, Р. Гонсалес Принципы распознавания образов. Пер. с англ. - М.: Мир, 1978г.